

中文

 2023-03-03 14:38:34
2023-03-03 14:38:34


“人工智能应用落地的‘高歌猛进’,是有人在‘负重前行’。”
王博士(化名)作为清华大学智能产业研究院自动驾驶课题组的一员,负责车路协同数据集的训练工作。
课题研究中,王博士在电脑上要处理成千上万张图片:每一张图片,道路轨迹、建筑形状都不尽相同,一张图片里可以拆分出好几个标签,这是他每天都要面对的“复杂”标注题。
“我们拿到这些文件之后,可以挖掘出很多信息,然后不断地去进行标注。既要保证标注的效率,也要保证质量,这样才能训练出更精准的AI模型。”

图片来源:清华大学智能产业研究院官网
自动驾驶,是清华大学智能产业研究院的研究课题之一。作为一所面向第四次工业革命的国际化、智能化、产业化研究机构,这里汇聚了来自全球的国际顶尖科学家、产业变革领袖和世界级研创团队。
他们站在国际科技前沿,引领中国的科技创新,探索着自动驾驶、生物计算、绿色计算等领域的未解之谜。
AI“更懂”人类的背后,是大量数据训练的结果。
时逢2022年的9月,清华大学智能产业研究院的多项科研工作都在和时间赛跑。就在这时,清华大学智能产业研究院的十多个课题组感受到了AI研究工作的“阻力”,“给图像做标注时,图片迟迟加载不出来;检索图片,系统也要卡很久。”
原来,训练AI数据集需要存储大量数据,数据量很快就达到百TB级,而传统存储阵列在庞大的数据量面前“不堪重负”,没有展示出最佳的性能、可扩展性等能力,导致科研工作者们在实际操作时遇到了卡慢问题。
面对存储性能提升的难题,信服云EDS为清华大学智能产业研究院设计了高性能文件存储方案。480TB存储空间配置完成后,有了充足的存储空间,科研工作者们可以放心地开展AI训练的工作。
01一个可以尽情“驰骋”的存储底座,
背后是信服云EDS“刚柔并济”的实力。
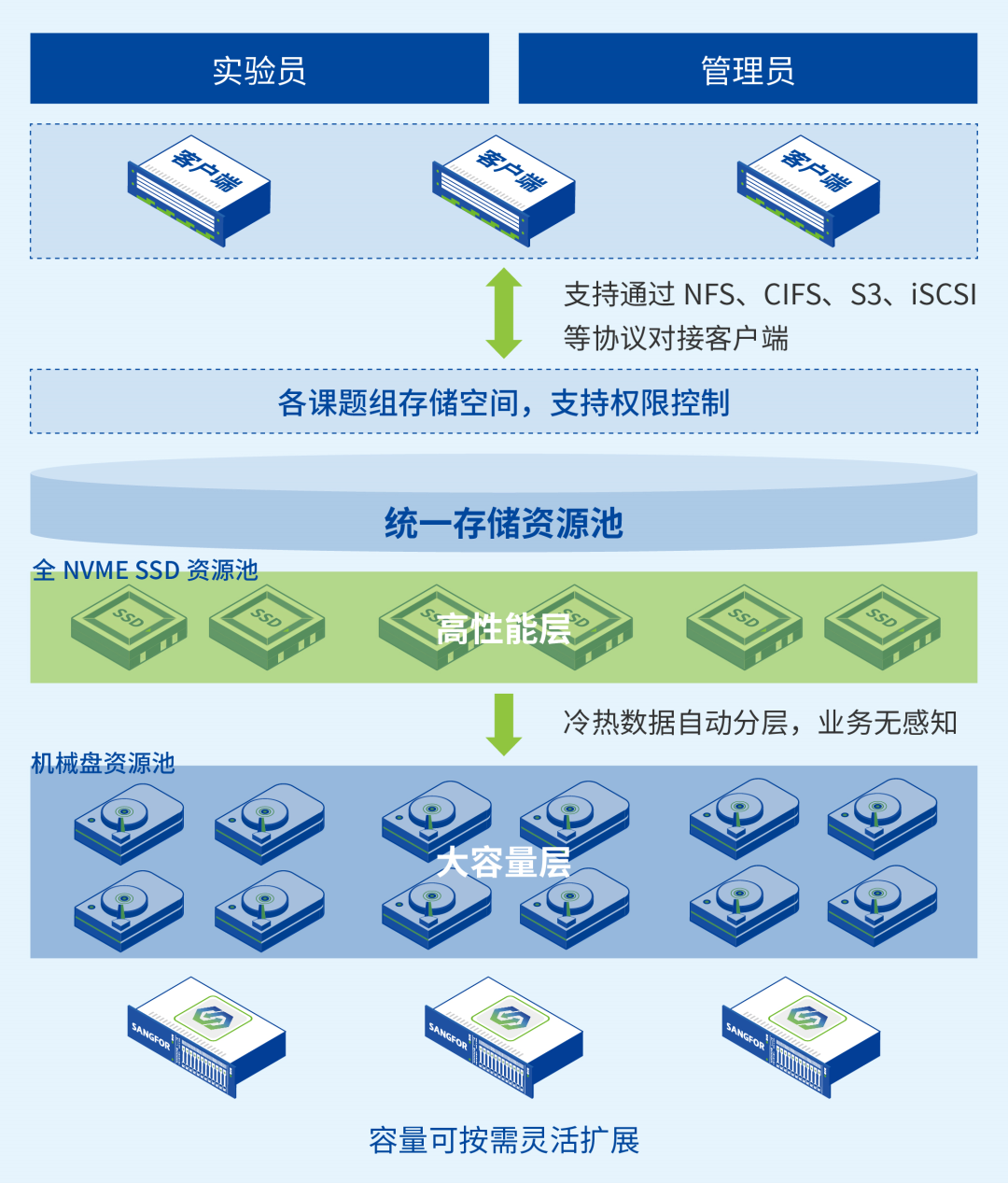
在硬件上,信服云EDS采用通用的X86服务器搭配NVMe固态硬盘的组合形式,构建存储高性能层,这使得训练集群访问数据时,可以优先经过高性能层的缓存加速,相较于传统磁盘阵列,存储性能有了大幅提升。
在软件上,信服云EDS通过自研的分布式高性能文件系统,利用小文件合并、phxkv分布式元数据库、智能预加载等自研技术,提高KB级小文件的元数据和数据处理效率,有效保障AI训练过程中访问数据的效率,并大幅缩短了科研中的AI训练时间。
对于清华大学智能产业研究院而言,选择一款存储产品首要关注的是性能。因为科研工作者在标注数据时,需要不停地读取文件和创建文件,频繁的操作中无疑会增加元数据的访问耗时,CPU算力也会受到影响,而信服云EDS让读写文件的性能彻底告别了卡慢。
其实,信服云EDS和用户的双向奔赴,不止于此。
02容量与性能的同步扩展,
见证千行百业的腾飞与发展。
“我们现在的容量使用率已经超过90%,但性能丝毫没有受影响。”除了提供稳定一致的性能表现,信服云EDS灵活扩展的能力,也在不断刷新用户的预期。考虑到研究院数据规模不断增长的情况,信服云EDS支持同时扩展容量和性能,这打破了传统存储架构的局限性。

在传统存储架构中,容量增长到一定程度,性能的增长不会相应增加,甚至还会出现性能下降的现象。而信服云EDS实现了容量和性能的同步扩展,在容量扩展的同时,存储性能也随之线性增长。以集群规模扩展至8节点为例,混合盘配置4KB随机读可达120万IOPS。
03故障闭环处理的设计,
是保障业务可靠运行的底气。
在注重高性能的同时,业务连续性和数据可靠性也不可忽视。为此,信服云EDS构建了完整的故障闭环处理框架:
在故障发生前,通过硬件亚健康预测、检测和数据多副本、纠删码等机制,帮助用户提前预防故障的发生;亚健康的可视化监控,则让用户感知硬盘健康状态,提前做好备件采购和替换准备工作。
在故障发生时,通过亚健康硬件自动隔离、智能数据修复、I/O路径自动切换等机制,自动处置问题,最大化减轻运维的压力,同时也保障了业务连续性和数据可靠性。如若发生人为误删除、恶意删除或超过冗余机制范围的故障等情况,可通过快照备份、回收站等机制快速找回数据。
这些高可靠的设计,也是用户坚定选择信服云EDS的理由之一。
截至目前,信服云EDS已经累计参与交付超过20000个客户和300+例PB级项目,在AI训练、卫星遥感、医疗影像、动漫制作、软件开发等场景获得了用户的广泛认可。

从蒸汽技术革命到信息技术革命,科技一次次改变着世界。
这一次,AI的想象力更是无限。这些面向未来交通、医疗、绿色发展的难题,也正在一步步被清华大学智能产业研究院的科学家们“拿下”:
▷ 发布全球首个真实场景车路协同数据集
▷ 研发出连续获得全球第一的自动化蛋白质结构预测平台
▷ 绿色计算5G网络智能减碳技术获得吴文俊人工智能科技进步奖
丈量寰宇,眺望星辰。在科技领航者的探索下,智能时代正以一种前所未有的清晰度呈现在我们面前。信服云EDS身处这个伟大的时代中,将集自身之所长,融用户之所需,助力科研工作者们在数据的浩瀚宇宙中,自由翱翔。




