

中文

 2024-05-13 18:41:05
2024-05-13 18:41:05


人的高矮胖瘦、颜值肤色、甚至天赋
都与基因密不可分
简单来说
每个人的独特性,源于他们的基因组

这个独一无二的生命编码
定义了我们每个人的独特性
也蕴藏着人体的生理健康信息
几乎所有疾病的发生
根源上都可以追溯到基因变异
基因检测,离我们有多远?
过去,一个人的基因组测序需要13年时间和30亿美元。这是人类基因组计划所付出的时间与成本。
今天,任何一个人只需提供2毫升的唾液样本,给专业机构进行检测。一周左右,你便能得到一份专属于自己的生命说明书,它可以帮助你了解自己的疾病倾向、遗传风险,从而采取预防措施,守护自己的健康。
目前,无创产前基因检测是测序应用最成熟的领域之一。此外,在肿瘤预防、诊断和治疗方面,基因检测也大有用处!
以山西医科大学为例。该校位于食管鳞癌发病率极高的太行山区,当地有些家庭,好几代人都饱受“难以吞咽”的痛苦。甚至,部分高发区的发病率和死亡率均是世界平均水平的10倍以上,位列全国食管麟癌发病率和死亡率首位。
学校发现,这一疾病的成因不仅与日常不健康的生活习惯,缺乏必需的微量元素紧密相连,遗传变异因素也在“捣鬼”。经过逾十年科学研究,学校成功鉴定了食管鳞癌早期的“突变频谱印迹”,识别出相关显著突变基因和信号通路,为食管鳞癌的早诊、早治和精准治疗提供科学依据。
一份基因检测报告≈30万本四大名著
几页薄薄的基因检测报告,实际却承载了科研工作者沉甸甸的社会担当,和对生命的关怀与守护。
那么,一份精准的肿瘤基因检测报告是如何诞生的呢?
通俗来讲,从采集肿瘤样本开始。它可能是微小的组织片段、血液、体液、甚至一个细胞。科研工作者通过二代测序(NGS)技术,找到发生变异的基因,从而为患者“量身定制”最合适的治疗方案。
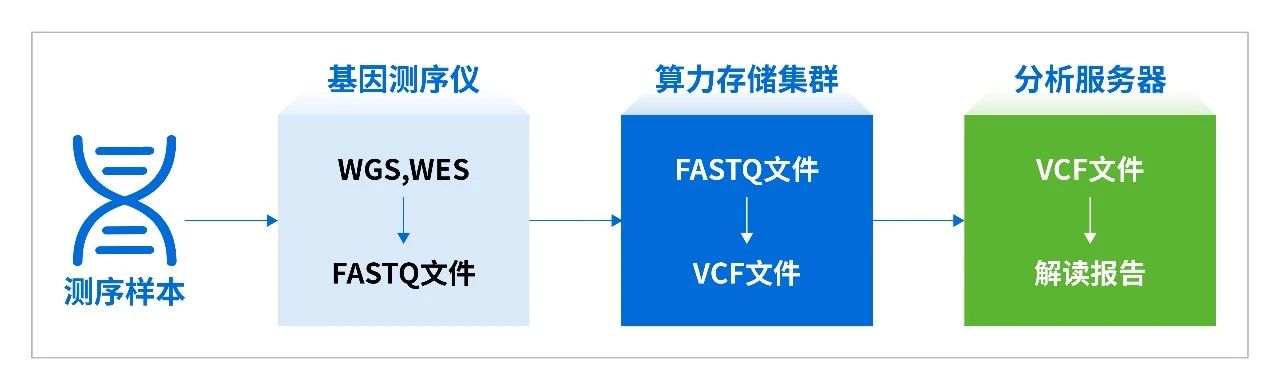
这个过程看似简单,实则复杂。“基因测序--数据分析--数据归档”,涵盖了一系列密集的生物信息分析工作,涉及海量的数据读写和处理。
想象一下:基因测序单样本原始数据量约为60~100GB,在DNA建库过程中,由于NGS扩增过程DNA序列也被过量扩增,整个过程中数据可能膨胀至5倍以上。这相当于30万本四大名著的电子版,或者150部高清电影的数据量。
山西医科大学每次基因测序至少新产生GB级结果数据,平均每天基因下机数据几TB到十几TB不等(含原始、过程、结果数据)。
数据量太太太太大,无疑是学校面临的最大挑战。它不仅直接影响了多业务部门间的数据共享,还降低了数据分析效率,增加了数据长期保存成本。
推动食管鳞癌科学研究这项关键任务,需要一个“存得下”、“跑得快”、“用得起”的存储底座来支撑。
时间缩减60%,成本降低30 %
深信服带着更适合基因测序,这一天然数据密集型业务的高性能分布式存储,来了~
该方案由3节点分布式存储集群组成,采用SSD+HDD混合的模式,以混闪的配置提供媲美全闪的性能体验,同时提供高达1.05PB数据存储能力。配置了12块3.84TB NVMe SSD,108块16TB的大容量HDD,轻松支撑起百亿规模文件的稳定运行。
针对基因测序的特殊存储需求,学校主要做了三项关键的优化:
60s弹性扩容,百PB级容量,业务零宕机,数据零丢失
考虑到学校测序仪每年200TB以上的数据增量,学校采用分布式存储Scale-out横向扩展模式,帮助学校实现按需、分钟级的灵活扩容。如同高铁列车,随乘客增多而增加车厢,且每个车厢都能供给动力,节点越多,数据处理的速度也越快。
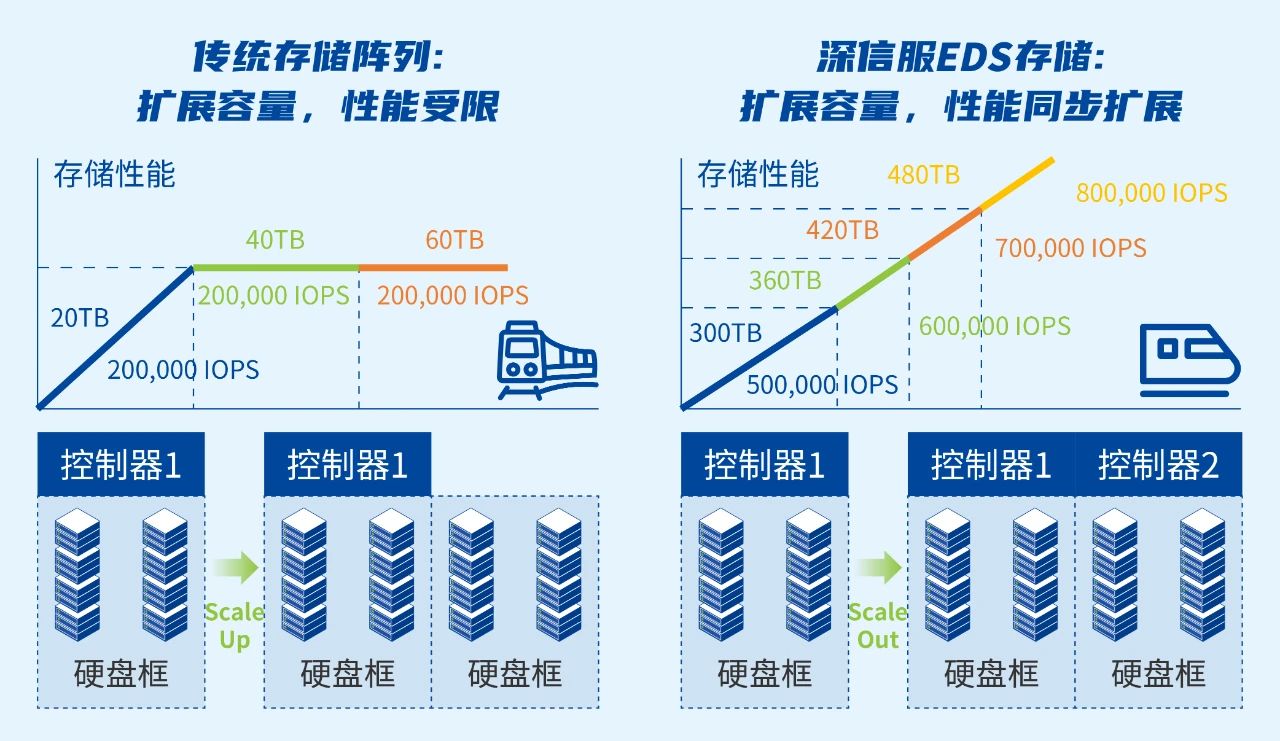
值得强调的是,即便是在多位科研人员,全天候7*24小时在线作业的极端情况下,它也可以保障业务不卡死,数据零丢失。
通过硬盘故障智能隔离来避免写入降级、端到端数据校验防止静默错误、创新性能无损快照等能力,实现99.9999%的高可靠性目标,保证测序数据0丢失,确保业务连续。
存储集群可在用户完全无感知的情况下,进行在线扩容,这意味着可以动态地添加或移除任一节点和硬盘,且即使面临亚健康磁盘,依然不会影响基因测序过程,且基因测序归档数据可靠保存。
多协议互通,动态IO整合,缩短时间60%,跑得快
在肿瘤基因测序过程中,单作业吞吐为GB/s级别,对存储提出了极高的挑战。
-
基因拼接需读写大量临时文件,单作业性能需求要几百MB/s;
-
基因比对过程文件追加写、原始文件顺序读、参考文件随机读、临时小文件写、单作业性能需求500MB/s以上;
-
基因注释输入文件顺序读、参考文件随机读、结果文件随机写、单作业性能1GB/s以上。
以上综合性能需求最高达10GB/s,随着科研需求不断增加,未来吞吐性能需求会更高。
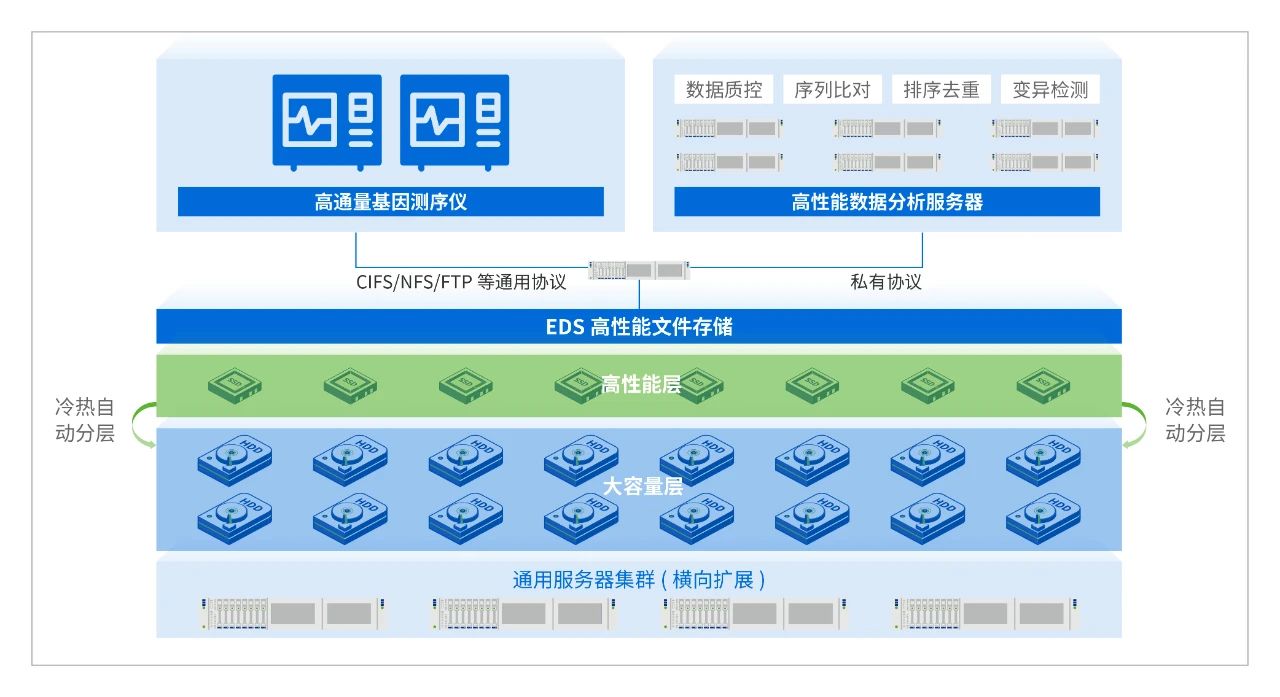
为提升数据的传输效率,通过深信服自研分布式存储,同时对接了基因测序仪和高性能计算节点。
在提升数据分析效率上,当原始的FASTQ数据从基因测序设备产生时,它们能够借助CIFS协议,被即时写入到EDS共享文件夹中,数据无须二次传输。随后,计算集群可以直接对这些原始数据进行访问和处理,从而显著减少数据传输的时间,加快整个测序流程。
利用NVMe-Of协议来最大化地发掘固态硬盘(NVMe SSD)的潜在性能。每个EDS节点都能够提供高达3GB/秒的带宽,轻松应对大文件的快速写入需求。
此外,通过RDMA技术,成功缩短了I/O的数据路径。显著提升了操作速率OPS,也增强了数据处理的吞吐能力。相较传统存储方案,可以缩减高达60%的基因数据分析时间,显著提升测序数据的处理效率。
另一个挑战在于,基因测序数据分析常常需要跨部门、跨学科的科研人员分工合作。不同团队之间的数据共享涉及大量的文件拷贝,这不仅低效还拖慢了分析进度。
深信服EDS高性能文件存储支持多协议融合通信,不同部门、不同终端,即使使用不同数据交互协议,数据也能灵活流动,高效访问,让整个基因测序和分析过程更流畅。
冷热分层,分级存储,节省成本30%,用得起
肿瘤基因检测数据是肿瘤精准诊疗的核心数据,通常需要保存至少5年。山西医科大学每年累积的数据量就高达200T以上,存储成本高,科研经费难以承担。
比如,那些被频繁调阅的基因组数据,就像我们日常爱穿的衣服,需要触手可及。这些数据就被存放于由NVMe SSD构建的高性能存储层,确保高速访问和处理。
而,对于那些几个月甚至更久未被查阅的数据,它们就像那些季节更替后压在衣柜底部的衣服。系统会自动将这些冷数据,迁移至成本更经济的大容量机械硬盘中。另外,对于更长久的数据留存也可以通过深信服自研数据压缩,进一步降低成本。这不仅优化了数据存取效率,还大幅降低了数据长期储存费用。
如此一来,在食管鳞癌的未来研究中,即便是历史较久的基因数据也能被有效地保留和利用,为科研人员提供宝贵的资源库,从而推动医学研究的进步。
经过一年多的稳定运行,“以前需要一周以上的NGS高通量肿瘤基因测序流程,现在最快3天以内就可以搞定。”山西医科大学食管鳞癌的科研老师们对此深有体会。

数字时代,基因测序已经飞入平常百姓家。
这背后,是科研人员孜孜不倦的追求,也是数字科技对生命的温暖守候。
截至目前,深信服EDS以其卓越的性能与可靠性,在AI、生物科技、多媒体娱乐、自然资源与实景三维、芯片与工业设计等多个数据密集型领域,服务超过20000名用户,累计实现35000 小时稳定运行。




