

中文

 2024-07-05 18:54:53
2024-07-05 18:54:53



本期焦点
越来越多用户采用虚拟化、超融合以及云平台环境来承载其核心业务,核心业务的高并发对性能的要求尤为严格,在VMware替换的热潮下,原VMware用户也更为关注新平台在核心业务上的性能表现是否对标,或实现超越。深信服将通过系列解析,为大家从不同维度分享提升平台性能的关键技术。
在当前用户的核心业务系统中,访存密集型应用越来越多,如金融行业的高频交易系统、风险管理系统;医疗行业的电子健康记录(EHR)系统、物流行业的仓库管理系统等。这些系统对于访存要求的提升,与其后端使用了很多如分布式缓存Redis、大数据处理引擎Spark,分析型数据库HANA、AI引擎/模型等服务组件有很大关系。以Redis为例,其为内存型数据库,内存访问速度会直接影响其性能表现。
NUMA作为当前主流的服务器CPU架构,在NUMA架构下,如何提升访存速度是虚拟化性能优化的重要课题之一。本文将详细解析深信服在NUMA架构优化方面的技术,展示如何通过这些技术提升虚拟化平台的性能,满足用户核心业务高并发运行的要求,以及在VMware替代过程中的性能需求。
NUMA架构背景
在早期的计算机系统中,通常只有一个处理器用于执行所有的计算任务。然而,随着计算机应用的复杂性和需求的增加,单个处理器无法满足高性能计算的要求,计算机系统逐渐向多核架构演进。
传统的多核方案采用的是SMP (Symmetric Multi-Processing) 技术,即对称多处理器结构。在SMP架构下,每个处理器的地位都是平等的,对内存的使用权限也相同。任何一个线程都可以分配到任何一个处理器上运行,在操作系统的支持下,可以达到非常好的负载均衡,让整个系统的性能、吞吐量有较大提升。但是,由于多个核使用相同的总线访问内存,随着核数的增长,总线将成为瓶颈,制约系统的扩展性和性能。
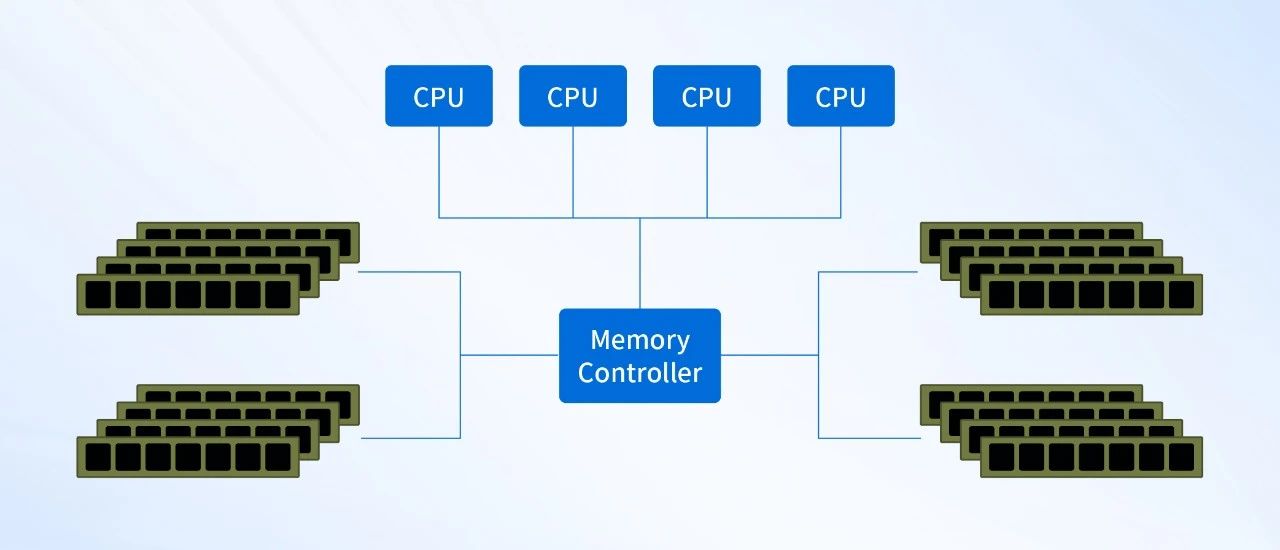
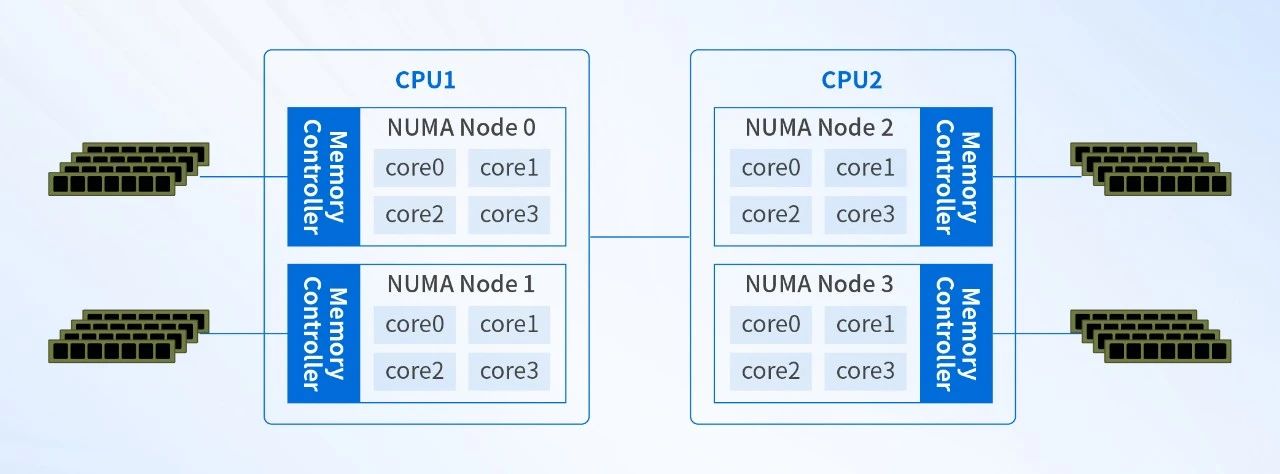
NUMA架构可以很好地解决SMP架构的内存访问瓶颈问题。在NUMA架构中,系统被划分为多个节点,每个节点包含一个或多个处理器、本地内存和I/O设备。节点之间通过高速互连网络进行通信,如HyperTransport (AMD) 或QuickPath Interconnect (Intel) 等,使处理器优先访问本地内存,降低内存访问延迟,提高了多处理器系统的性能。
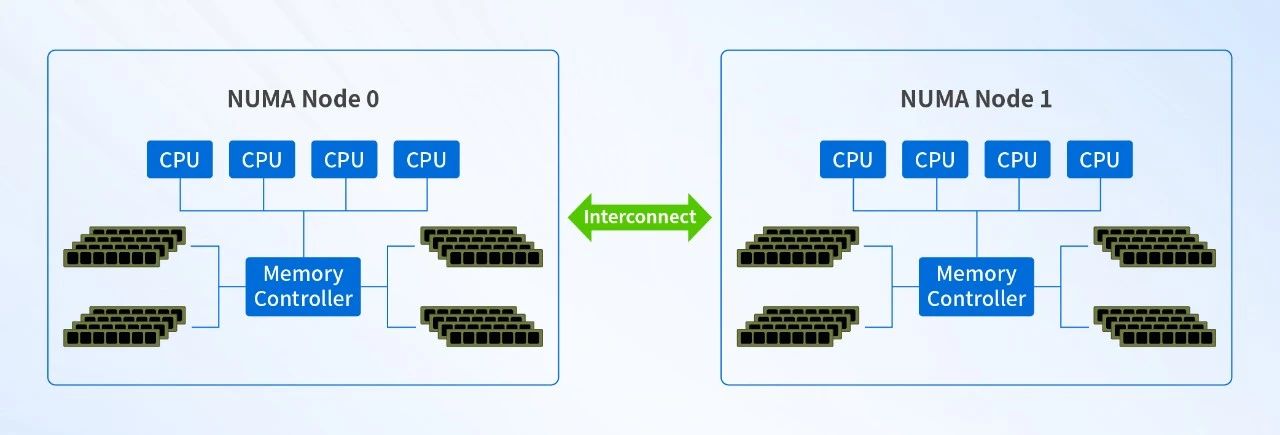
在NUMA中有三种节点类型:
-
本地节点:对于某个节点中的所有CPU,此节点称为本地节点。
-
邻居节点:与本地节点相邻的节点称为邻居节点。
-
远端节点:非本地节点或邻居节点的节点,称为远端节点。
CPU访问不同类型节点内存的速度是不相同的,访问本地节点的速度最快,访问远端节点的速度最慢,即访问速度与节点的距离有关,距离越远访问速度越慢。
Christoph Lameter博士在《NUMA: An Overview》一文中指出:2013年,高端商用服务器有两个NUMA节点,本地节点的随机内存访问时延为100ns左右,远端节点的内存访问时延需要增加50%。
NUMA引入挑战
在linux系统中,线程作为CPU调度的基本单位,对应CPU运行队列上的一个任务。内核会为每个任务选择一个相对空闲的CPU,但CPU的负载是动态的,内核实现了CPU的Load Balance机制,会往相对空闲的CPU上迁移任务。也就是说,默认情况下,任务可能在不同的CPU之间迁移。
在NUMA架构下,任务可能从Node 1上的CPU迁移到Node 2上的CPU,任务访问之前Node1上的内存数据,会造成跨节点CPU访问。虽然linux内核提供了NUMA Balance机制,周期性的迁移任务或者内存数据到本地节点,尽可能地让任务访问本地节点的内存,但无法100%避免远端内存的访问。
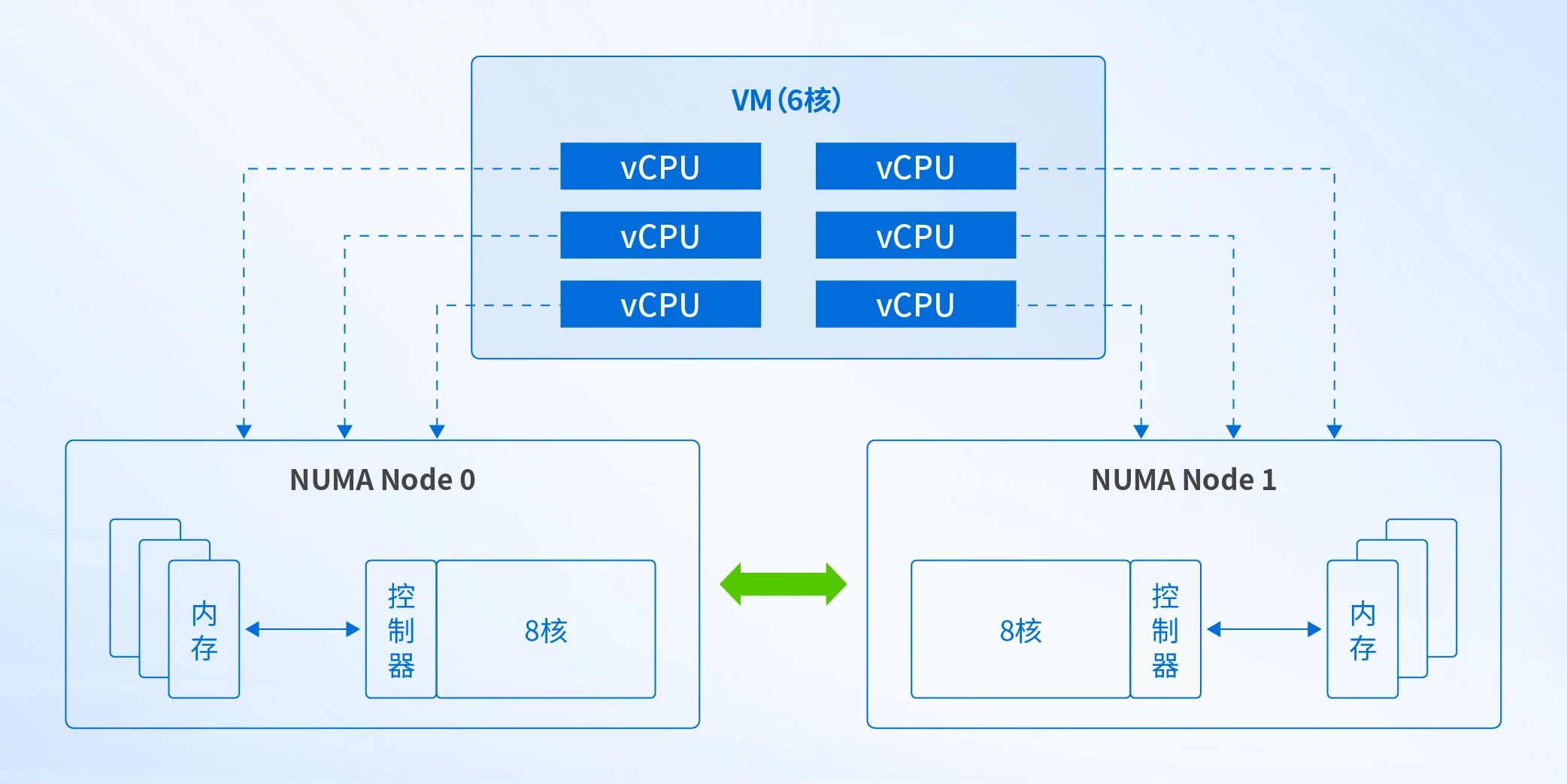
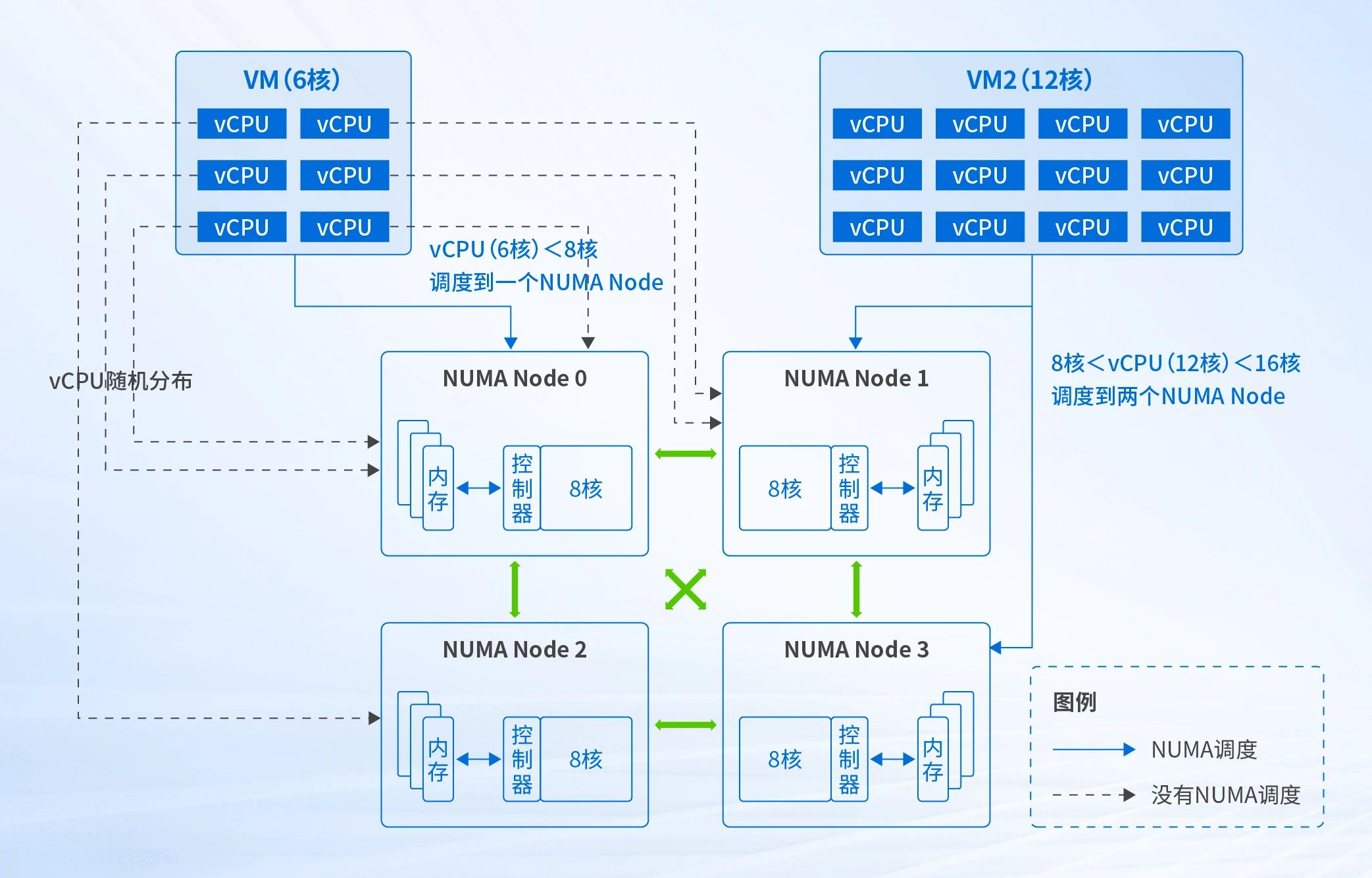
在虚拟化场景下,一个虚拟机的vCPU对应操作系统上一个线程(如下图),多个vCPU线程运行在不同NUMA节点上共享内存,或者vCPU线程在不同NUMA节点之间迁移,都会导致虚拟机跨NUMA节点访问,内存访问延迟增加。
业界NUMA调度技术机制
针对NUMA特性,业界主要有以下几种常见方案:
方案1:vCPU绑定物理核
需要手动设置vCPU绑定,vm资源优先绑定在物理机的同一个NUMA Node上。
方案2:指定虚拟机绑定的NUMA节点数量
手动配置绑定的NUMA节点数,会将vCPU和内存平均分配到相应数量的NUMA节点上。
方案3:自适应分配NUMA节点
调度程序会为虚拟机自动分配NUMA节点,虚拟机的CPU会被限制在NUMA节点上运行,优先使用本地内存,提高内存局部性。虚拟机的vCPU个数可能超过NUMA节点核的数量,单个NUMA节点无法容纳,会被分配到多个NUMA节点。为了提高内存局部性,支持将NUMA拓扑暴露给虚拟机,由虚拟机做最佳决策。同时在NUMA节点间迁移云主机,保证节点间的Load Balance。
从使用上看,方案1、2限制较多,使用上不是很方便,对VM的CPU数量有要求,并且静态绑定可能导致NUMA节点间负载不均衡。因此,方案3比较常见。
深信服NUMA调度技术详解
深信服超融合主要采用自适应的NUMA调度,自适应NUMA调度能够做到NUMA之间的负载均衡,同时减少vCPU远程内存访问,提升整体的性能。
自适应的NUMA调度在不同类型应用中优化效果明显,特别对于一些内存操作的中间件。我们在虚拟机中分别部署DM8(达梦数据库)、Redis和memcache,分别在开启和关闭NUMA调度的场景下执行基准测试。从测试数据看,开启NUMA调度后,中间件性能明显提升。
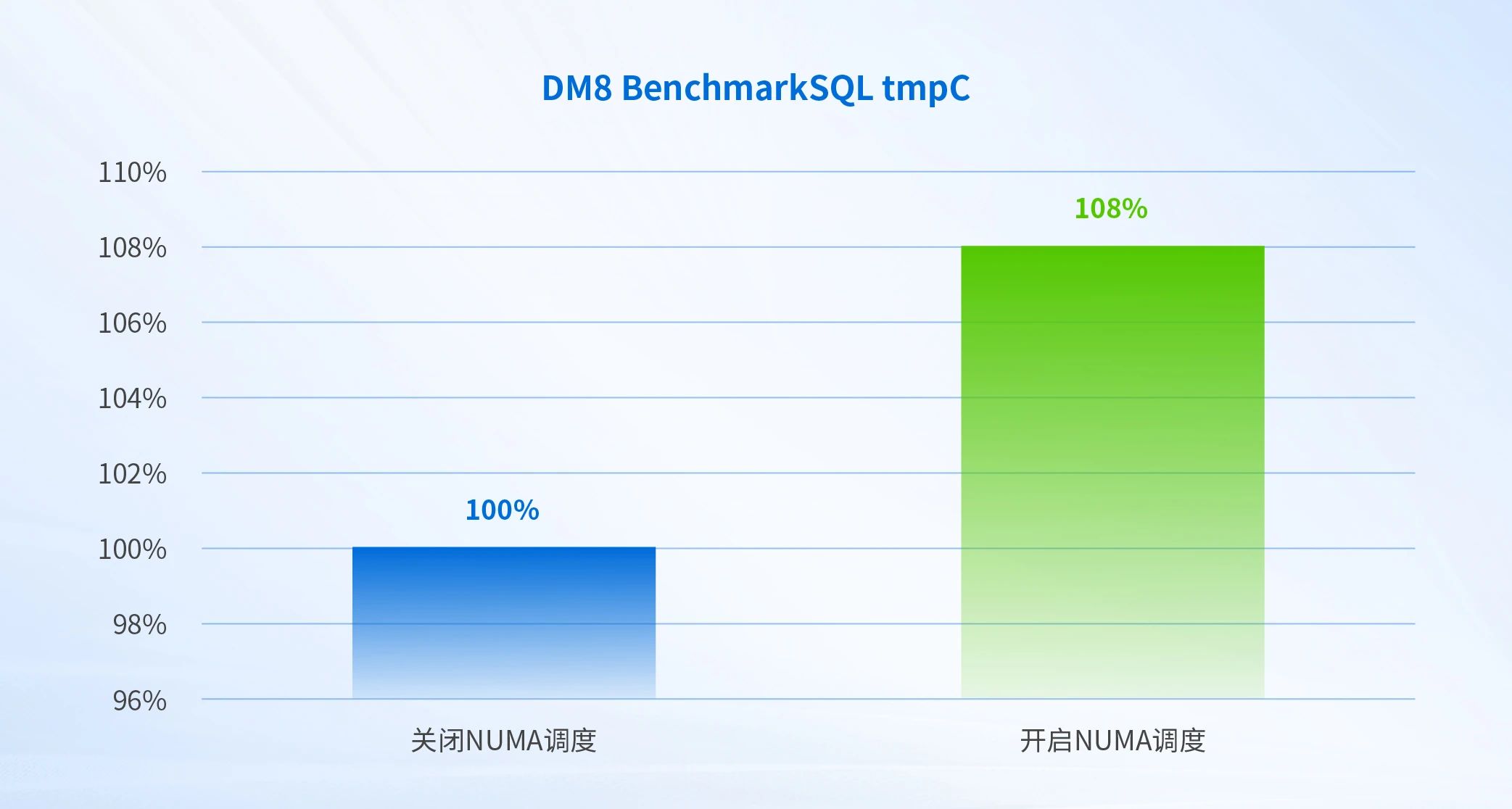
BenchmarkSQL是一个关系型数据库的基准测试工具,通过对数据库进行 TPC-C 标准测试,即模拟多种事务处理:新订单、支付操作、订单状态查询、发货、库存状态查询等,从而获得最终的tpmC值。tmpC表示每分钟可以处理多少个新订单,值越大代表性能越好。通过BechmarkSQL V5.0来对达梦数据库dm8运行基准测试。
下图表示启用NUMA调度对应用的相对性能改进,Y轴的100%表示关闭NUMA调度测出来的tmpC指标权重。
redis-benchmark是Redis官方提供的性能测试工具,我们通过redis-benchmark 对Redis V7.2.5进行压测,在关闭/开启NUMA调度场景下,分别测试SET/GET长度为1KB的value的QPS指标。QPS表示每秒的读写操作数。
测试命令及参数:
- redis-benchmark -t get -d 16 -c 100 -n 6000000 -r 60000000
- redis-benchmark -t set -d 16 -c 100 -n 6000000 -r 60000000
下图表示启用NUMA调度对应用的相对性能改进,Y轴的100%表示关闭NUMA调度测出来的QPS指标权重。

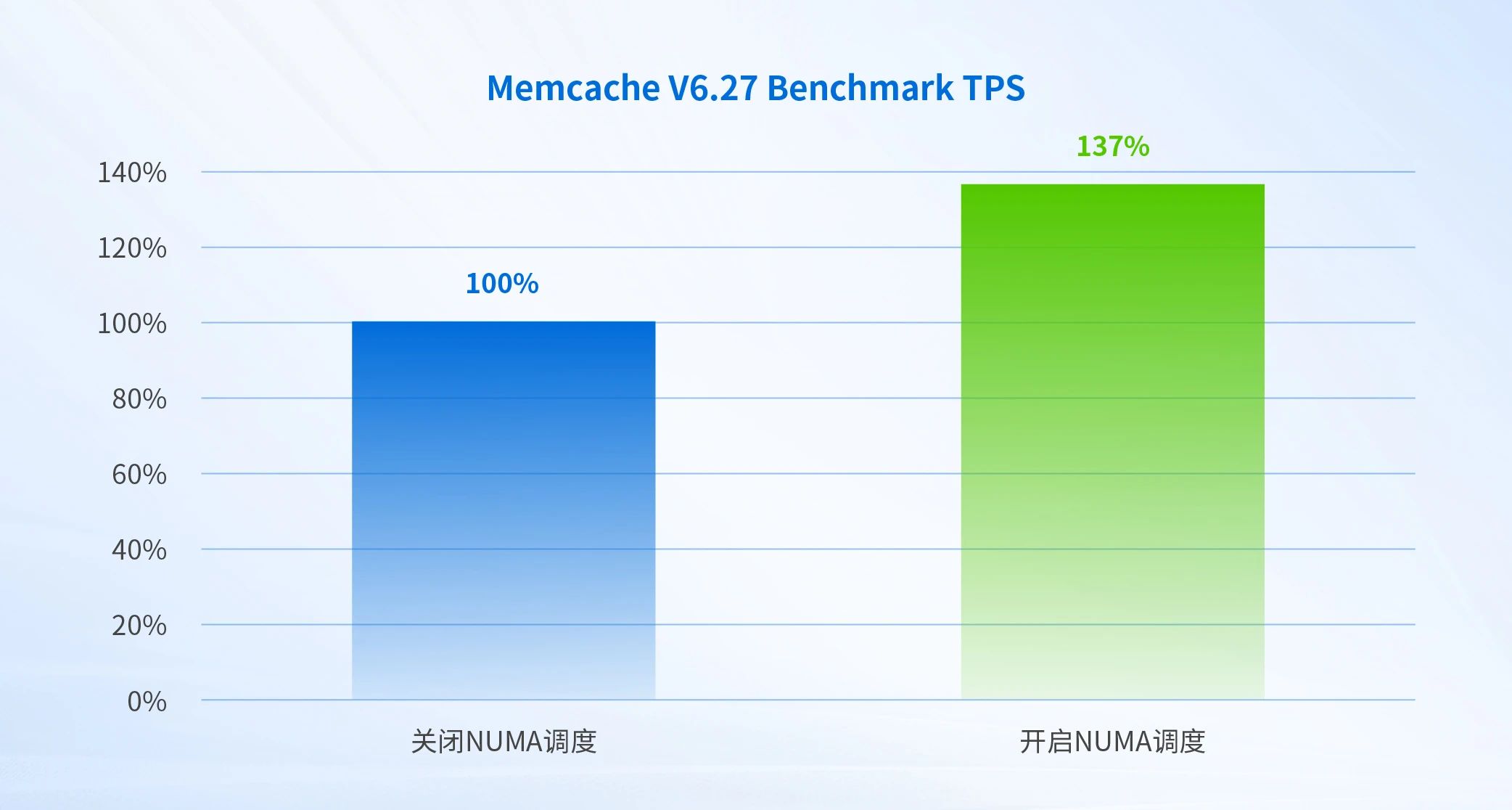
memaslap是Memcache自带的性能测试工具,我们通过memaslap对Memcache V6.27压测,在关闭/开启NUMA调度场景下,分别测试value长度为1kb的TPS值。TPS表示每秒事务数。
测试命令及参数:
- memaslap -s 127.0.0.1:11211 -t 300s -T 8
下图表示启用NUMA调度对应用的相对性能改进,Y轴的100%表示关闭NUMA调度测出来的TPS指标权重。
从上面的测试数据看,对于访存密集型应用优化效果比较明显。以下为具体实现原理。
自适应分配NUMA节点
自适应地将虚拟机的vCPU进行划分后调度到NUMA节点,减少虚拟机vCPU远程内存访问。如图,自动为虚拟机选择合适的NUMA节点,当虚拟机vCPU数量小于NUMA Node的核数时,则将调度到一个NUMA节点上。当虚拟机vCPU数量大于NUMA 节点的核数时,则将调度到多个NUMA Node上,同时会将vNUMA拓扑暴露给虚拟机,由虚拟机做出最佳决策。
为了保证NUMA节点的负载均衡,在放置虚拟机时,会考虑NUMA节点间的负载情况,选择一个负载较低的节点。同时,在虚拟机运行过程中,结合NUMA节点负载,会对虚拟机在NUMA节点之间进行迁移。优先保障重要虚拟机所在NUMA节点负载更低,能够避免CPU、内存带宽以及Cache资源的相互抢占。
信创场景优化
信创服务器NUMA节点多,NUMA间的距离也不一致,NUMA节点的核数也相对较少。
针对信创服务器的NUMA特点,我们会识别NUMA节点之间的距离,优先将同一个虚拟机多个vNUMA放置到相近的pNUMA上。
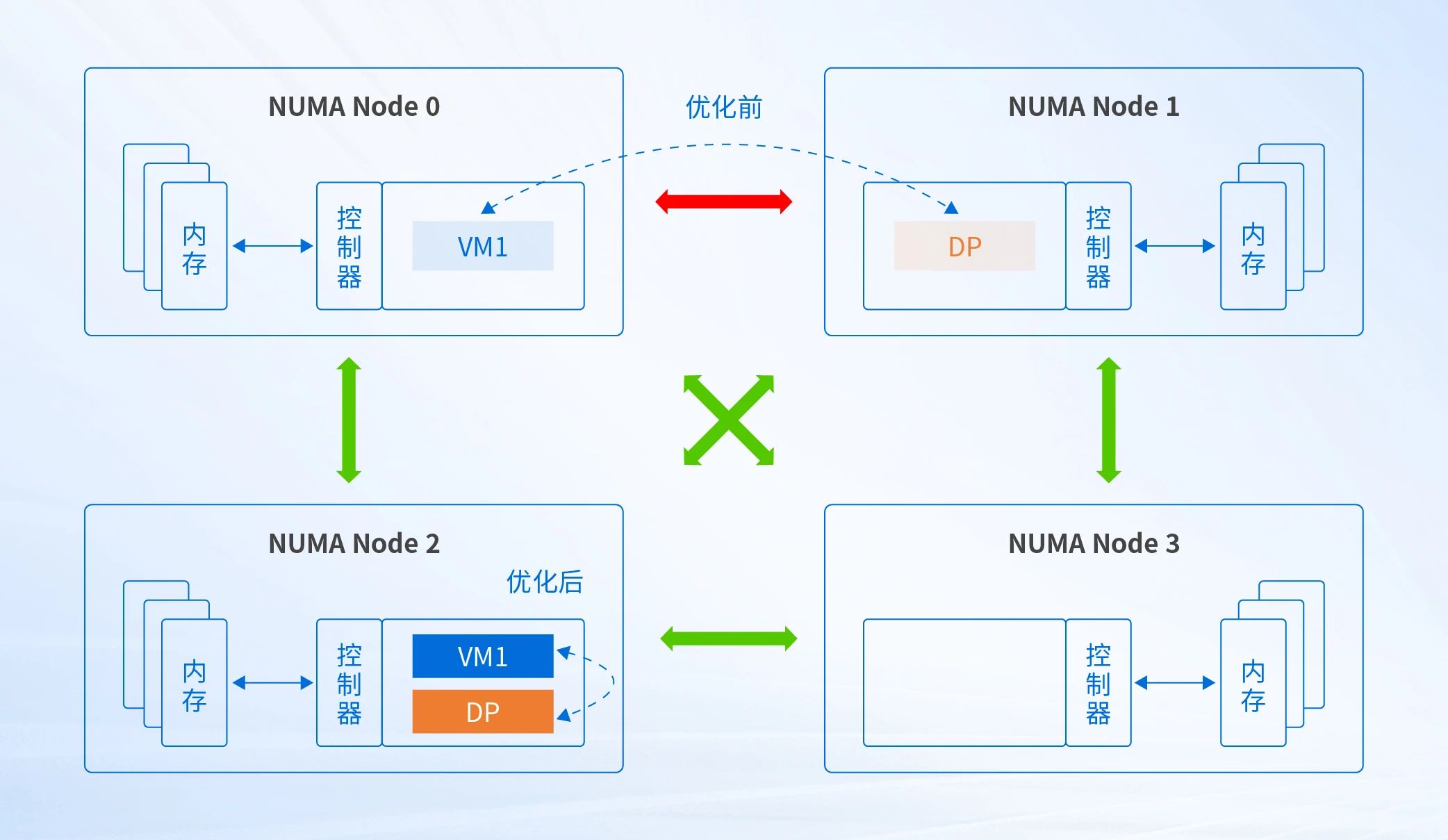
为了进一步在信创场景下提高数据转发性能,深信服为底层虚拟化设计开发NUMA亲和性功能,即对虚拟机和数据转发进程进行强关联,调度到同一个NUMA节点上,使用本地内存访问,提高数据转发的性能。如图,DP为数据转发进程。
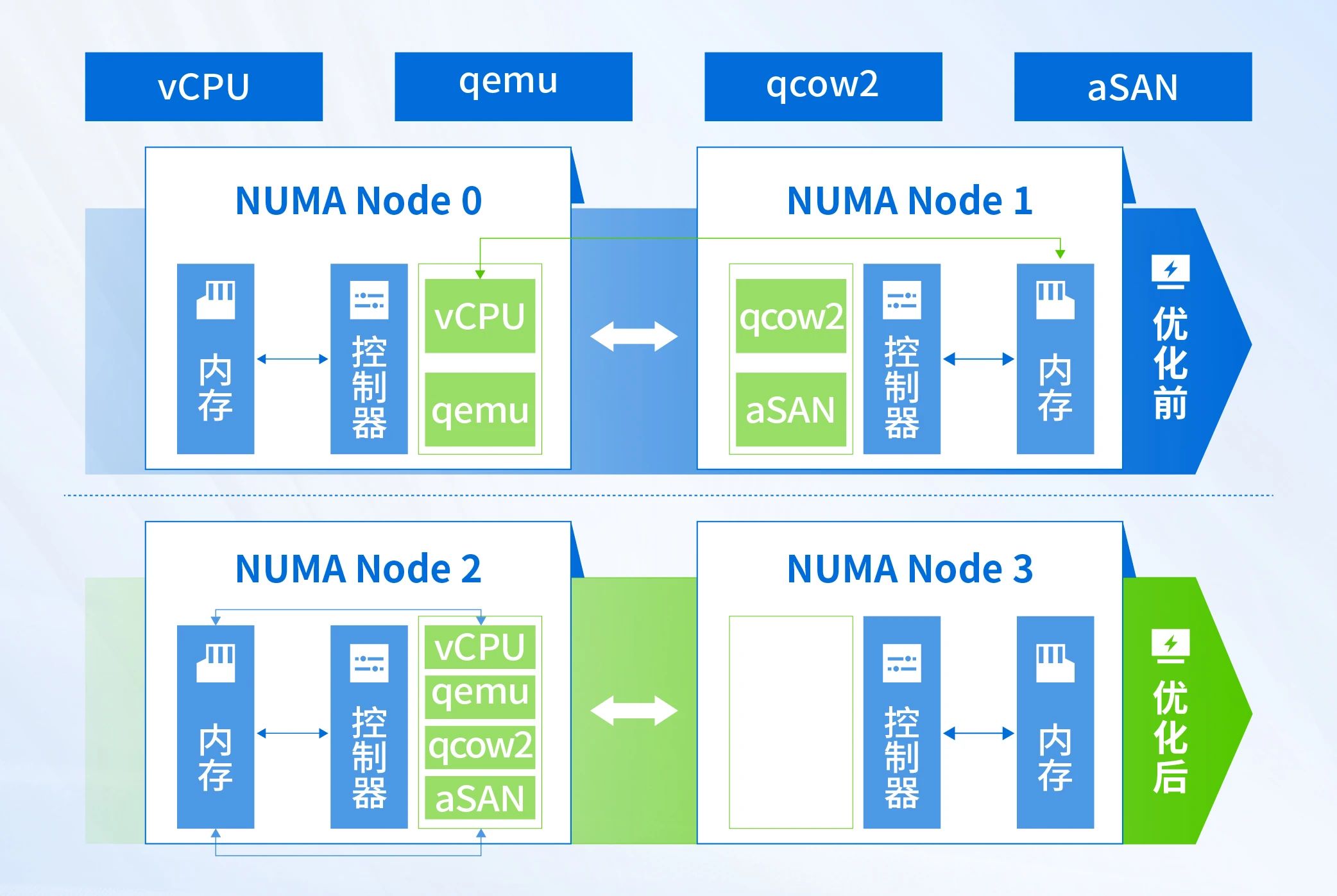
为了最大程度发挥NUMA的优势,在存储层面将一条完整IO上的vCPU、qemu、libnfs、aSAN等进程调度到同一个NUMA Node(如下图),避免内存远端数据访问,并使用大页内存机制提高访存性能,降低数据处理过程中的开销,提升IO流处理效率。
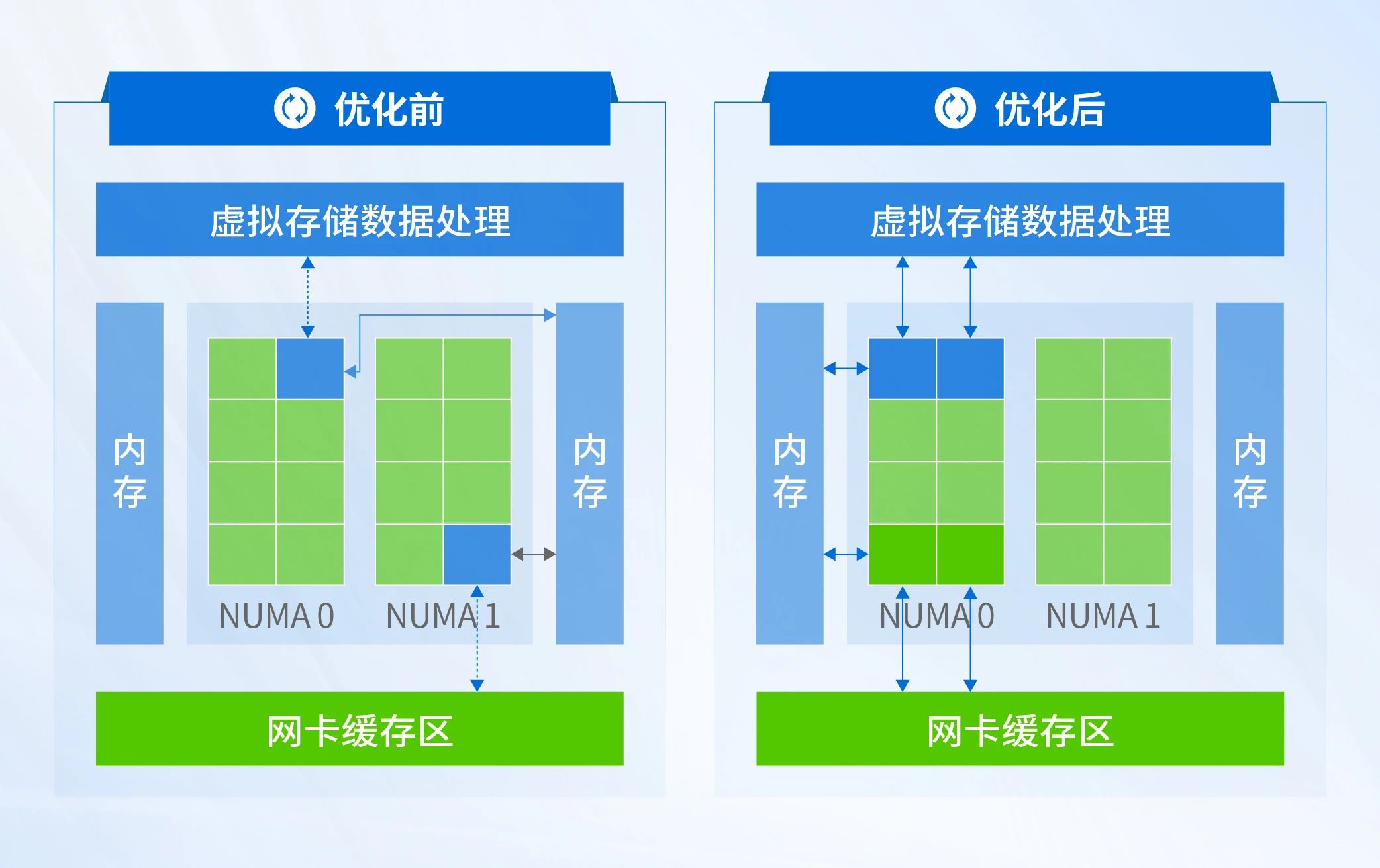
数据在从网卡缓存区传输到虚拟存储的过程中,需要经过各自的CPU线程进行处理。而随着网卡性能提升,单核CPU缓存转存的效率成为瓶颈,且跨NUMA的远端访问也会降低效率。让网卡可以被多个CPU进行处理,同时对其进行NUMA亲和,既打破了缓存转存的瓶颈,也可以降低传输延迟,更大程度地提升并发性能,提升虚拟机高深度大块写性能20%以上。
与业界方案的对比分析
- 行业支持情况:
- H厂商支持在页面上配置虚拟机每个vCPU运行到哪个NUMA节点;S厂商不支持;VMware支持自适应NUMA调度。
深信服平台自适应将虚拟机的vCPU进行划分后放置到NUMA节点,减少虚拟机vCPU远程内存访问。相比页面配置每个vCPU运行位置,深信服自适应NUMA调度能够自动进行虚拟机vCPU的划分和放置,并且在NUMA之间进行均衡,减少vCPU远程内存访问,提升整体的性能。
相比VMware,深信服通过创新研究院和云产品线的合作研究,深度结合我们自己的业务场景以及平台服务情况,增加了存储服务的NUMA调度、重要虚拟机识别、信创场景适配、虚拟机网络亲和等,提升调度效果。
总结
深信服的NUMA自适应调度基于各场景做了深度适配优化,进一步提升应用的内存访问速度:
-
自适应将虚拟机的vCPU进行划分后放置到NUMA节点,减少虚拟机vCPU远程内存访问。
-
在不同的NUMA节点之间进行迁移,保障NUMA节点之间负载均衡。
-
识别重要虚拟机,保障重要虚拟机所在NUMA节点负载更低,能够避免CPU、内存带宽以及Cache资源的相互抢占。
-
针对信创服务器多NUMA且NUMA间距离不一样的场景,增加了识别NUMA节点之间的距离,优先将同一个虚拟机多个vNUMA放置到相近的pNUMA上。
-
支持虚拟机网络亲和选项,勾选后将虚拟机调度到和网络数据面相同的NUMA节点,提高数据转发的性能。
-
不仅对虚拟机进行NUMA调度,对存储服务也会进行相应的NUMA调度。
UnixBench测试实例
UnixBench是一个广泛使用的基准测试工具,用于评估类Unix系统(包括UNIX、BSD和Linux)的性能。它通过一系列测试来衡量系统的各种性能指标,如CPU、文件系统、内存和进程等。
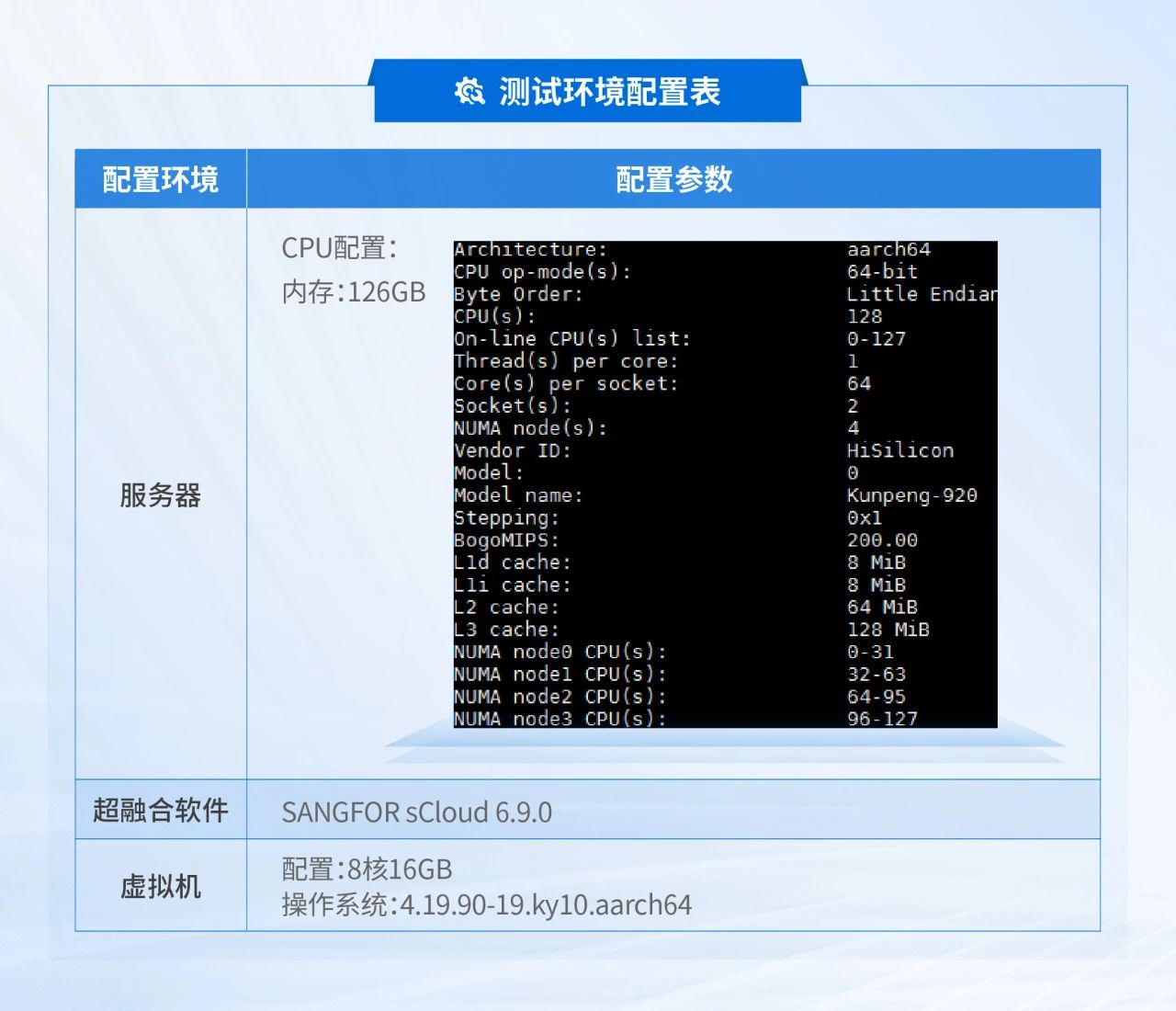
测试环境说明:


测试结果:
在落地版本HCI 6.9.0中,我们能达到如下效果。在后续版本的优化中,我们仍持续保持该项技术效果的领先。
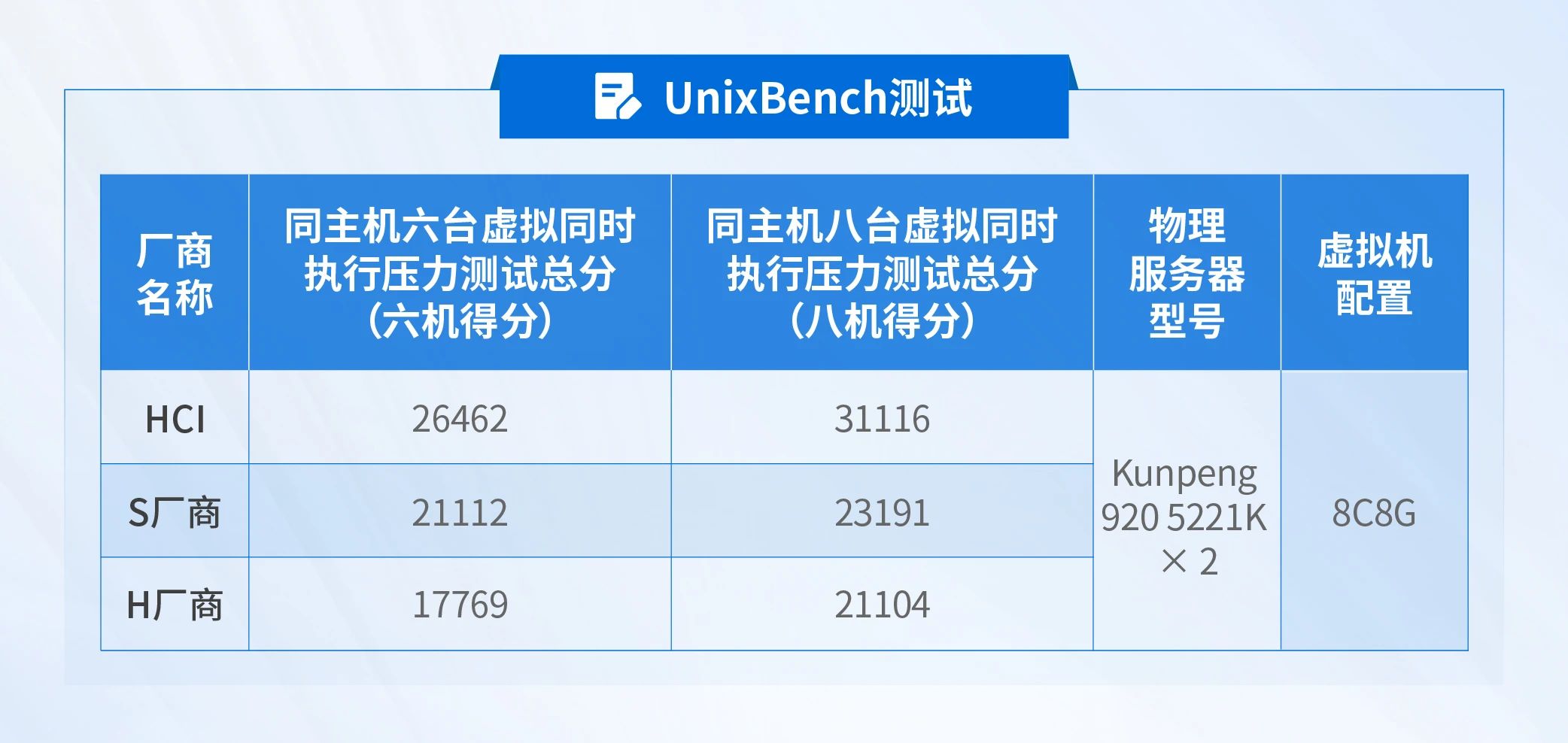
超融合启用NUMA时,UnixBench测试结果如下:
同主机六台虚拟机结果相较于S厂商高出20.2%,同主机八台虚拟机得分相较于S厂商高出34.17%。
云话技术是深信服打造的一档云技术内容专栏,将定期为大家推送云计算相关的技术解析、场景实践等内容,为大家深度解析深信服在云计算领域的创新能力、技术动态、场景应用及前瞻分析等内容。




