

中文

 2019-03-15 00:00:00
2019-03-15 00:00:00


在数字化转型的浪潮中,各行各业对业务上云的建设需求与日俱增。但是很多企业管理者们对核心业务能否上云仍然举棋不定,担心业务云上运行会降低业务稳定性。在上一期信服君给大家介绍了深信服分布式存储如何突破性能极限,本期信服君就带领大家深入了解深信服超融合如何做到稳定为王,可靠承载用户核心业务的。
为了承载用户核心业务并稳定运行,深信服超融合从硬件到业务层等多方面进行了升级优化:
- 硬件层面,通过最佳实践部署避免单点故障,良好的兼容性助力承载各种核心业务,对于硬件的亚健康检测能够帮助用户提前对可能存在问题的硬件进行排查。
-
平台层面,深信服超融合采用分布式架构,任意节点故障都不会影响平台的稳定性,内置可靠中心能够对数据中心整体运行状况进行把控。
-
虚拟机层面,节点资源调度能够保障集群资源使用尽可能均衡,虚拟机HA(High Availability高可用性集群)确保出现节点故障时,虚拟机自动在合适的主机拉起并继续运行,同时资源热添加(DRX)能够自动为繁忙业务添加资源,避免业务卡慢甚至宕机。
- 业务层面,Oracle和SQL server的优化能够平稳运行高并发业务系统,内置的容灾和双活方案为整个数据中心的故障提供了有效保障。
在贴近用户业务需求的背后,是深信服超融合对稳定性能的不断强化和改进:
链路高可靠
深信服存储私网是“池化”存储卷内所有主机和硬盘资源之间的关键桥梁,存储卷内数据流通所采用的独立的以太网络。为了满足不同场景下的部署方案,存储私网支持三种网络部署方式:无链路聚合、单交换机链路聚合和双交换机链路聚合。
采用不同的存储私网部署模式,可以为平台带来不同程度的高可靠性,最佳实践推荐双交换机链路聚合的部署方式,这是容错能力最高的部署方式,任一线路或者交换机故障都不影响存储卷的正常运作,而且能够将主机间的存储通信带宽扩大。
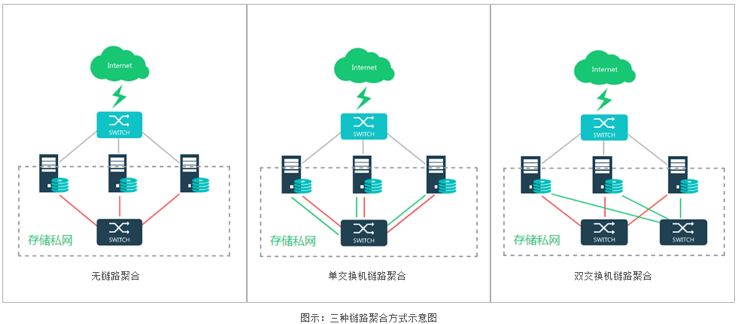
存储私网链路聚合按照TCP连接进行均分,两台主机间的不同TCP连接可使用不同物理链路。区别于传统的链路聚合采用主机IP进行均分的方式,即每2台主机间只能用1条物理链路。存储私网的链路聚合除了能够提高网络可靠性,还能够有效提升存储通信的网络带宽。
可视化可靠中心
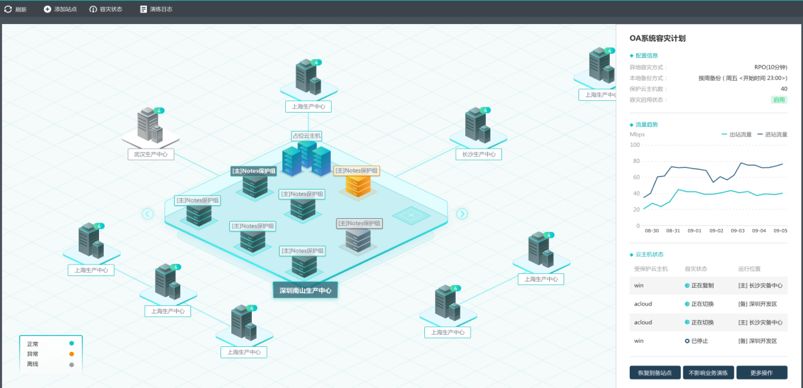
为了用户能够及时甚至提前预测问题,深信服可靠中心能够从硬件、平台、虚拟机、业务层面等各维度对平台运行情况进行监控。通过可靠中心,用户可以随时随地掌握数据中心整体运行情况,对风险进行提前预判,一旦出现异常,还能通过邮件或者短信及时通知管理员。
▲深信服企业级云管理平台
极简灵活的副本机制
副本机制,是指将数据保存多份的一种冗余技术,由分布式存储的副本复制模块来保证副本的一致性和副本之间的同步。底层管理的副本对上层服务是透明的,上层不感知副本的存在。
深信服超融合支持两副本和三副本,副本所存放的位置必须满足主机互斥原则,即不可能存在两个副本同时存在同一台主机上。
以两副本为例
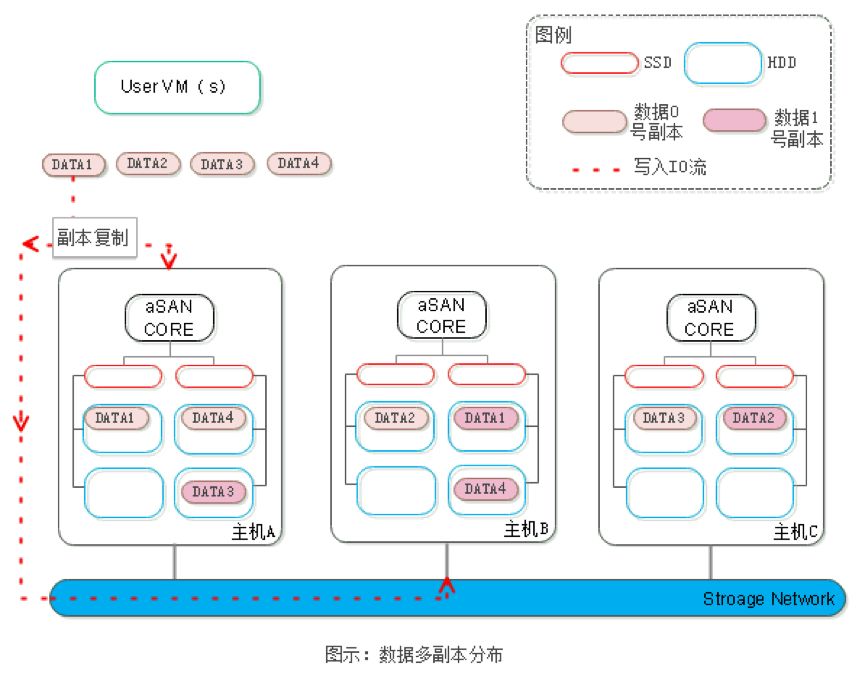
若写入一段数据,该数据依次经过条带化和分片之后,会再经过副本复制模块,分别写入到不同的主机中。在无故障的情况下,为保证副本数据的一致性,两个数据副本必须都写入完成后,这段数据才算写入成功。
若读取一段数据,会选择其中任意一个副本进行读取,优先本地副本读取数据。在没有网络掉线、硬盘故障等异常情况下,文件副本数据是始终保持一致的,不会区分所谓主副本和备副本。
如下图所示,对于每个DATA都有两份副本位于两台主机上。
自愈式数据重建
深信服分布式的高可靠特性除了通过多副本机制能够保障存储卷内的组件(磁盘或主机)发生物理故障时,故障组件上的数据还有另外的副本存储在其他的组件上。还有数据重建能够实现故障快速自愈、存储私网聚合保障链路高可靠、仲裁机制防数据脑裂等。
以数据采用两副本策略为例,当存储卷内的组件(磁盘或主机)发生物理故障时,故障组件上的数据还有另一的副本存储在其他的组件上,仍然可以保障虚拟机的正常读写,但此时存储卷的冗余度实际上已变低,假如此时另一副本所在的组件也发生故障,就会导致数据丢失。
通过数据重建功能,在组件发生故障后,将以故障组件上数据的另一副本作为修复源,以分片为单位在目的组件上重建出新的副本,恢复副本的完整性,实现系统自愈。
虚拟机故障漂移
对于外部环境故障(比如主机网线断了,所在存储不能访问等)和虚拟机Guest系统故障两种情况导致的业务中断问题,深信服的超融合平台都提供了成熟可靠的HA机制保障业务不中断或短暂中断。
HA通常需要两个或者两个以上的主机节点组成集群,当启用了HA功能的虚拟机所在节点发生意外(主机掉电、断网等)时,集群心跳机制侦测到后,将选择一台资源充足的节点自动重启该虚拟机,从而实现业务的不中断或短暂中断。
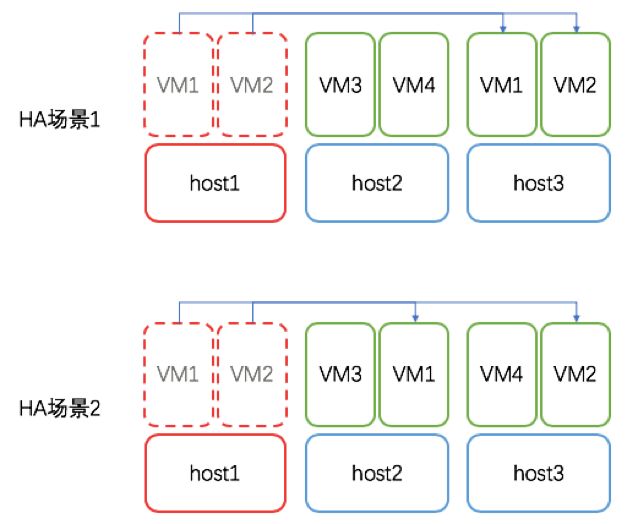
集群心跳机制,通过轮询的机制,每隔5s检测一次虚拟机状态是否异常,当发现异常并持续时长达到客户设置的故障检测敏感度时(比如5分钟),切换HA虚拟机到其他主机运行。
如下图所示,当云主机存储不能正常访问时,必定会启动HA机制,其他故障场景HA机制可根据需要自由配置:
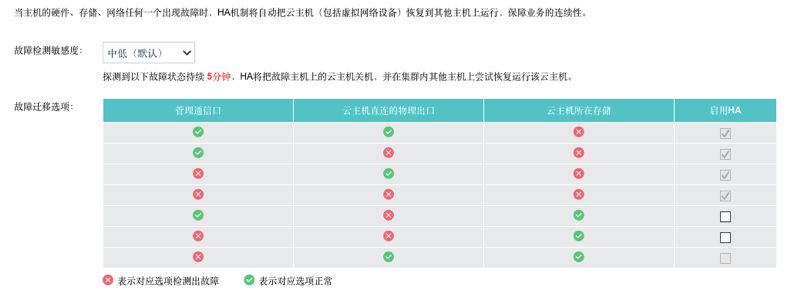
通过深信服超融合的HA技术,对业务系统提供了高可用性,极大缩短了由于各种主机物理或者链路故障引起的业务中断时间。
分布式资源调度(DRS)
在虚拟化环境中,如果生产环境的应用整合到硬件资源相对匮乏的物理主机上,虚拟机的资源需求往往会成为瓶颈,全部资源需求很有可能超过主机的可用资源,这样业务系统的性能无法得到保障。
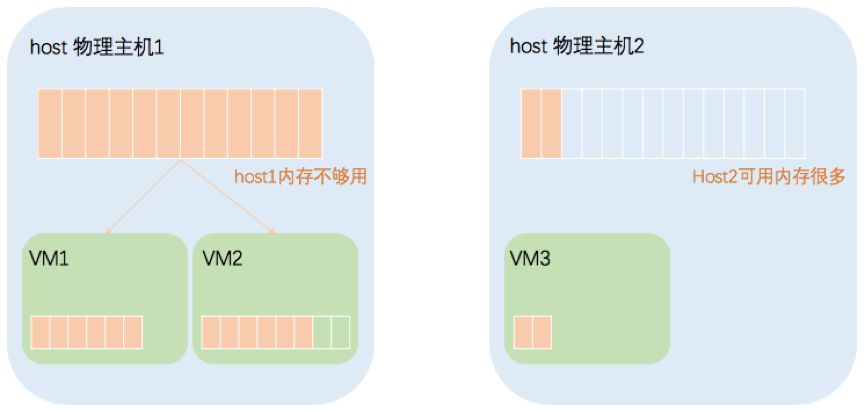
深信服超融合平台提供的动态资源调度技术,通过引入一个自动化机制,持续地动态平衡资源,将虚拟机迁移到有更多可用资源的主机上,确保每个虚拟机能及时地调用相应的资源,保障业务系统的性能。即便大量运行对CPU和内存占用较高的虚拟机(比如数据库虚拟机),只要开启了动态资源调度功能,就可实现全自动化的资源分配和负载平衡功能,也可以显著地降低数据中心的成本与运营费用。
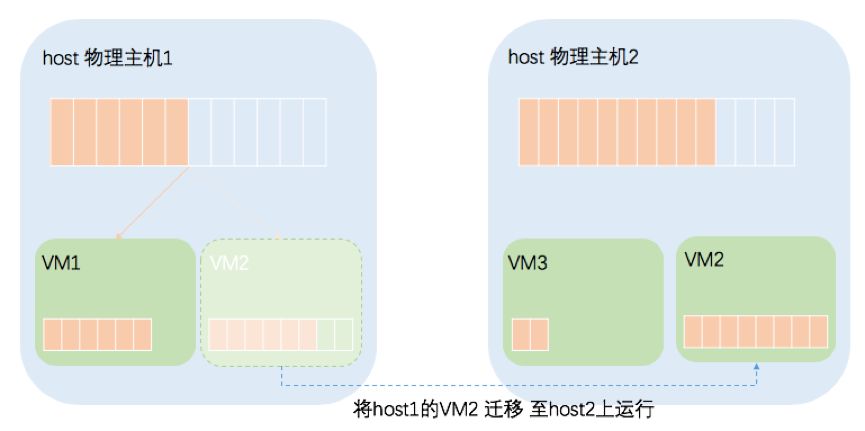
通过跨越集群之间的心跳机制,定时监测集群内主机的CPU和内存等计算资源的利用率,并根据用户自定义的调度策略来判断是否需要为该主机在集群内寻找有更多可用资源的主机,以将该主机上的虚拟机通过虚拟机迁移技术迁移到另外一台具有更多合适资源的服务器上,或者将该服务器上其它的虚拟机迁移出去,保证某个关键虚拟机的资源需求的同时不影响业务。
动态资源扩展(DRX)
服务器部署在虚拟化环境中,如果前期规划资源不充足或者随着业务量的增加导致原有资源规划不足,但这种情况下又无人值守,无法及时添加资源,就会导致业务会因为资源的不足受到影响。
动态资源添加与动态资源调度都是在业务运行资源不足时保障业务的正常运行。两者不同处是动态资源调度监控的对象是物理主机剩余资源,进行调度的单位为虚拟机;而动态资源添加关注的是业务虚拟机的资源消耗,进行资源调度的单位为资源(CPU、内存和存储)。
当启用动态资源添加功能之后,系统能够根据添加策略自动调整业务虚拟机资源,以保障业务的正常运行。资源动态添加功能,能够非常有效地利用主机资源,并且全自动化以减少运维成本。
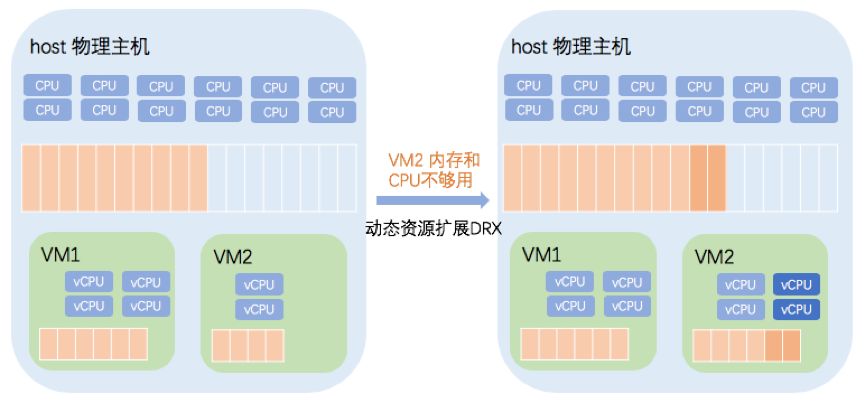
资源动态添加的实现原理很简单。系统实时监控业务虚拟机的内存,CPU资源的消耗,当资源消耗达到自定义阀值的时候对业务所在主机剩余资源进行校验。如果发现主机资源剩余量比较充足的时候,会对业务虚拟机进行不中断业务地添加资源。如果主机剩余资源不足的时候,不会进行任何资源调整操作,这样可以避免影响该主机上的其他业务。
容灾双活
在数据保护方面,为了预防人为的或者逻辑故障出现,深信服超融合提供了快照、备份等功能,对于关键业务,还能够提供秒级的CDP(持续数据保护),客户能够回滚到3天内任意一秒的状态点。对于多数据中心场景,可以实现异地容灾,甚至是核心业务的业务双活深信服也能提供完整的解决方案。总的来说,根据用户业务场景的不同要求,深信服可以提供相应的解决方案。
深信服超融合一直秉承极简、稳定、高性能的价值主张,为各行各业用户的核心业务上云交付省心、安全的产品和解决方案。迄今为止,深信服超融合已服务了全球4000+家用户,遍及政府、金融、医疗、教育、运营商、大企业等各行各业。




