

中文

 2024-02-26 18:09:56
2024-02-26 18:09:56


2月10日,Sam Altman在社交平台表示:OpenAI每天产生约1000亿的文字数据。

2月16日,OpenAI推出Sora。通过文本指令,Sora可以直接输出长达60秒的视频,并且包含高度细致的背景、复杂的多角度镜头,以及富有情感的多个角色。以Sora生成的《东京街头》视频为例,视频大小为46.1MB。
可以预见,此后,Sora每天产生的数据量将更加惊人。
Sora来了 呼唤卓越存力
生成式AI新应用对算力、算法要求高,对存储底座同样要求高。而且随着数据量的激增,存储成本也在上升。
OpenAI公布的Sora技术文档显示,在训练Sora时需要先用预训练模型把大量的、大小不一的视频源文件编码转化为统一的patch表示,再把时空要素提取作为transformer的token进行训练。单就开展这项工作,就对存储的性能、容量以及数据的处理速度提出了极高的要求。同时,技术文档也说明了,数据集越大,大模型效果越好。
这就意味着,如果想要训练用户自己的大模型,必须有一个高性能的存储底座来支撑。而一套真正符合AI训练需求的存储系统,应该是在提供卓越性能的同时,不给用户带来过多的经济压力。高性能可以确保AI训练的数据快速读取和写入,从而提升整体训练效率;同时要降低存储整体成本,让高性能存储“飞入寻常百姓家”。

OpenAI官网Sora生成的视频截图
为AI而生 深信服EDS存储实现训推一体
不久前,我们发布了统一存储EDS 520 版本,是一款专为AI大模型打造的统一存储平台,可以实现数据采集、标记、训练、推理和归档的全流程承载。
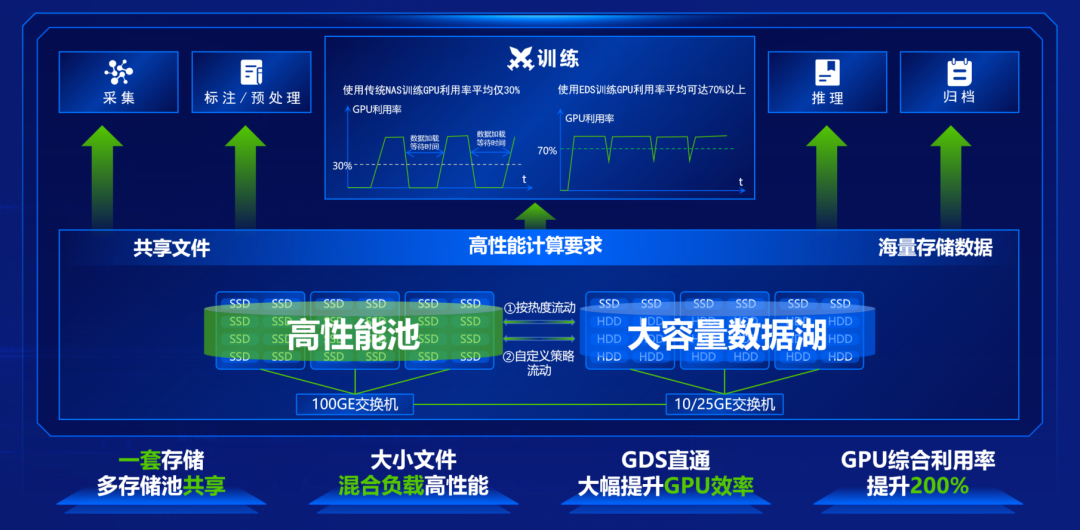
一套存储满足AI大模型开发全流程的数据需求
基于NFS+技术优化的存储系统,通过RDMA技术、多路径并行访问以及多级缓存机制,在4K小文件混合读写IOPS和1M大文件混合读写吞吐方面,分别达到行业领先水平的1.7 倍和5.7倍,3节点吞吐达到120GB/s,RDMA多路径带宽性能比TCP单路径提升将近50倍,将训练阶段GPU平均利用率从传统存储的30%提升至70%。
这样的设计不仅提高了大模型处理数据的效率,结合更高的读写速度和OPS,让大模型在读取或输出视频数据时能达到更快速度;而且增强了系统的灵活性和扩展性,使大模型应用可以应对各种类型和规模数据的处理需求,让大模型训练可以更高效地管理和存储数据。
此外,在高性价比上,深信服EDS存储实现了单TB可用容量成本降低50%,帮助用户降低了AI模型训练的总体成本。实现硬件成本降低的同时,还基于深舟数据管理平台对数据的高效压缩和管理能力,64GB可以承载亿级以上规模小文件的高速读写。
AI训练数据命中率达90% 清华大学的高性能存储实践
清华大学智能产业研究院是一所面向自动驾驶、生物计算、绿色计算等领域进行探索的国际化、智能化、产业化研究机构。
在其开展AI训练工作过程中,数据规模达到数十亿,并且还在不断增长,出现了数据调阅延时高、GPU训练效率大打折扣等问题。采用深信服EDS存储后,AI训练数据命中率达到90%,小文件读写时延降低到us级,百亿规模样本数据可以极速处理,有效保障AI训练过程中访问数据的效率,并大幅缩短了科研中的AI训练时间。
随着AI向着大模型多模态演进,AI训练伴随高并发数据分析,且生成式AI新应用急剧爆发,亟需高性能的存储底座来支撑。深信服EDS存储520版本正是为AI而生的全新一代存储产品,我们希望为千行百业的大模型开发提供极致性能的存力底座,让数字化惠及千行百业。




